FreeOCR
Scanning OCR Software
Latest release: March 2015 v5.4
Totally free OCR software for Microsoft Windows
Import Directly from Twain scanners, PDF and popular image formats
FreeOCR
|
|||
|
Scanning OCR SoftwareLatest release: March 2015 v5.4 Totally free OCR software for Microsoft Windows Import Directly from Twain scanners, PDF and popular image formats
|
||
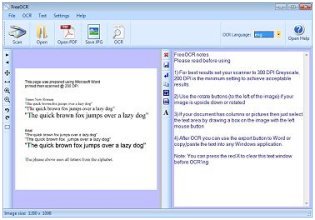
About FreeOCRFreeOCR is a free Optical Character Recognition Software for Windows and supports scanning from most Twain scanners and can also open most scanned PDF's and multi page Tiff images as well as popular image file formats. FreeOCR outputs plain text and can export directly to Microsoft Word format.
Free OCR uses the latest Tesseract (v3.01) OCR engine. It includes a Windows installer and It is very simple to use and supports opening multi-page tiff documents, Adobe PDF and fax documents as well as most image types including compressed Tiff's which the Tesseract engine on its own cannot read .It now can scan using Twain and WIA scanning drivers. FreeOCR V4 includes Tesseract V3 which increases accuracy and has page layout analysis so more accurate results can be achieved without using the zone selection tool.
Scanning SoftwareAs well as OCR FreeOCR can scan and save images as JPG's and we are currently working on "Scan to PDF" capability with the option to save as searchable PDF
OCR EngineThe included Tesseract OCR PDF engine is an open source product released by Google. It was developed at Hewlett Packard Laboratories between 1985 and 1995. In 1995 it was one of the top 3 performers at the OCR accuracy contest organized by University of Nevada in Las Vegas. The Tesseract engine source code is now maintained by Google and the project can be found here: http://code.google.com/p/tesseract-ocr/ LicenseFreeOCR is a freeware OCR & scanning software and you can do what you like with it including commercial use. The included Tesseract OCR engine is distributed under the Apache V2.0 license.
|
|